본 논문은 MoA 방법론을 통해 여러 LLM의 집단적 강점을 활용하는 새로운 접근 방식 프레임워크를 제안한다.
MoE에서 영감을 받았다고 본 논문에서 언급하고 있으며, 기존 MoE 구조는 단일 모델 내에서의 확장이였다면
MoA는 파라미터 추가 조정 없이 LLM Agents의 집단 전문성을 활용한 계층 구조이다.
https://arxiv.org/abs/2406.04692
Mixture-of-Agents Enhances Large Language Model Capabilities
Recent advances in large language models (LLMs) demonstrate substantial capabilities in natural language understanding and generation tasks. With the growing number of LLMs, how to harness the collective expertise of multiple LLMs is an exciting open direc
arxiv.org
1. Introduction
LLM은 최근 몇년 간 자연어 이해 및 생성 분야에서 많은 발전을 이루었다.
방대한 양의 데이터로 pre-trained하며 이후 인간의 선호와 일치하도록 조정되어 유용하고 일관된 출력을 생성한다. 그러나 LLM은 모델 크기와 훈련 데이터에 대한 본질적인 제약이 여전히 존재한다.
이러한 LLM을 추가 확장하는 것은 막대한 cost, 수 조개의 토큰에 대한 광범위한 retraining이 필요하다.
서로 다른 LLM은 고유한 강점을 가지고 있으며 다양한 task에 전문화 되어있다. 예를 들어 일부 모델은 복잡한 instruction 수행에 뛰어나고, 다른 모델은 코드 생성에 더 적합할 수 있다.
그렇다면, 여러 LLM의 집단 전문성을 활용하여 더 능력있고 강력한 모델을 만들 수 있을까? (capable & robust model)
본 논문에서의 대답은 “예”이다. LLM의 협력적 특성이라는 고유한 현상을 발견했다고 한다.
이는, LLM은 다른 모델의 출력을 받을 경우 더 나은 응답을 생성하는 경향이 있으며, 심지어 다른 모델의 자체 성능이 떨어지더라도 해당된다.
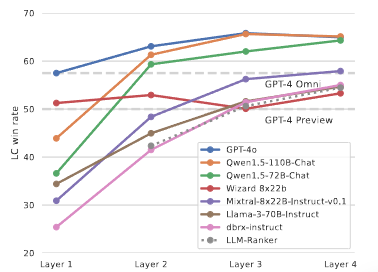
AlpacaEval 2.0 LC win rates
아래 그림은 6개의 인기 LLM에 대한 AlpacaEval 2.0 Benchmark에서의 LC 승률을 보여준다. 이 LLM 모델들이 독립적으로 생성된 답변을 제공받으면, 그들의 LC 승률이 향상된다.
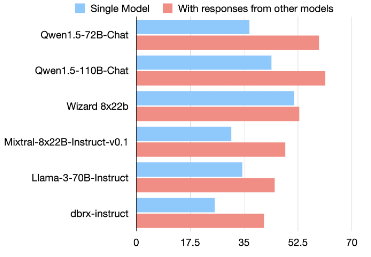
이는 협력 현상이 LLMs 사이에 널리 퍼져 있음을 나타낸다.
이러한 개선은 다른 모델들이 제공하는 보조 응답이 개별 LLM이 독립적으로 생성할 수 있는 것보다 낮은 품질일때도 발생한다.
본 논문은 이에 따라 여러 LLM을 활용하여 생성 품질을 반복적으로 향상시키는 혼합 Agent 방법론 (MoA)을 소개한다.
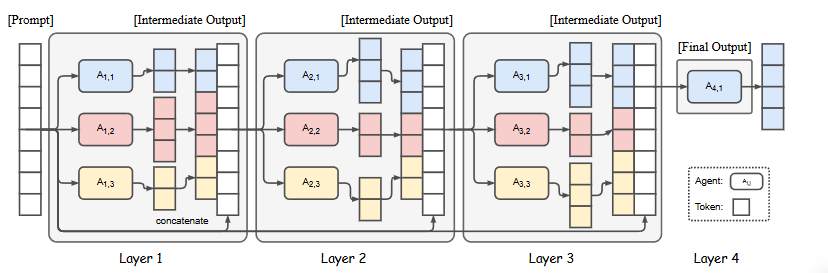
본 논문에서 제시하는 Mixture-of-Agents(MOA)의 구조를 그림으로 나타낸 것이다.
위에서 언급했듯이 여러 LLM 에이전트들을 계층적으로 구성하여 각 계층의 에이전트들이 이전 계층 에이전트들의 출력을 참고하여 응답을 생성한다.
- 계층적 구조: MoA는 여러 Layer로 구성되어 있다. 각 계층은 여러개의 LLM Agent를 포함한다.
- Agent: 각 Agent는 주어진 prompt에 대해 응답을 생성한다. 이때, 이전 계층의 모든 Agent의 출력을 추가 정보로 활용한다.
- 반복적 개선: 각 계층의 Agent들은 이전 계층의 응답을 바탕으로 자신의 응답을 개선한다. 이 과정을 여러 번 반복함으로써 최종적인 응답의 품질을 높인다.
- 최종 출력: 마지막 계층에서는 하나의 LLM을 사용하여 최종 출력을 생성하고, 이를 평가 지표로 사용한다.
첫번째 Layer의 LLM들은 Agent A1,1,…, A1,n 으로 표시되며 주어진 prompt에 대해 독립적으로 응답을 생성한다.
출력은 다음 Layer인 A2,1,…,A2,n의 Agent에게 제공되며 (여기서 첫 번째 Layer의 모델을 재사용할 수도 있음) 추가적인 정제(refinement)를 위해 전달된다.
이 반복적인 과정을 더 견고하고 포괄적인 응답을 얻을 때까지 여러 사이클동안 계속된다.
LLM 모델 간의 효과적인 협업을 보장하고 전체 응답 품질을 향상하기 위해, 각 MoA Layer에 대한 LLM의 신중한 선택이 중요하다. 이 선택 과정은 두가지 기준에 따른다.
1. Performance Metrics: Layer i의 모델 평균 승률은 Layer i+1에 포함될 적합성을 결정하는데 중요한 역할을 한다. 따라서 입증된 성능 지표에 따라 모델을 선택하면 더 높은 품질의 출력을 보장할 수 있다.
2. Diversity Considerations(다양성 고려): 모델 출력의 다양성도 중요하다. 다양한 모델에 의해 생성된 응답은 동일한 모델이 생성한 응답보다 더 많은 기여를 한다.
위 두가지 기준을 통해 MoA는 개별 모델의 결함을 완화하고 협동적인 합성을 통해 전체 응답 품질을 향상시키고자 한다.
AlpacaEval 2.0, MT-Bench, FLASK Benchmark를 사용하여 다양한 차원에서 응답 품질을 평가하는 포괄적인 평가를 수행한다.
본 논문의 MoA를 통해 AlpacaEval 2.0에서 GPT-4 omni를 제치고 SOTA를 달성했다.
The contributions
- 여러 LLM의 강점을 활용하기 위해 설계된 MoA Framework를 제안한다.
- LLM 간의 내재된 협력성을 강조하며, 모델들이 다른 모델의 출력을 사용할 수 있을 때 더 높은 품질의 응답을 생성하는 경향이 있음을 보여준다. 심지어 해당 출력이 더 낮은 품질일지라도 마찬가지이다.
- 최첨단 LLM 성능: MoA Framework는 SOTA를 달성했다.
2. Mixture-of-Agents Methodology
MoA 방법론에 대한 소개이다.
Collaborativeness of LLMs
LLM의 협력성을 입증하는 것부터 시작한다. 특히 다른 모델의 출력을 참조할 수 있을 때 더 높은 품질의 응답을 생성하는 능력에 중점을 둔다.
다수의 LLM 협력으로부터 최대의 이점을 추출하는 중요한 경로는 각 모델이 협력의 다양한 측면에서 어떻게 잘 수행되는지를 특성화하는 것이다. 협력 과정에서 LLM을 두가지 뚜렷한 역할로 분류할 수 있다.
- Proposers(제안자): 다른 모델이 사용할 수 있는 유용한 참고 응답을 생성하는 데 특화되어 있다. 좋은 제안자는 반드시 스스로 높은 점수를 받는 응답을 생성하지는 않지만, 더 많은 맥락과 다양한 관점을 제공해 최종 응답의 품질 향상에 기여해야 한다.
- Aggregators(집합자): 다른 모델의 응답을 단일 고품질 출력으로 통합하는데 특화된 모델이다. 자신의 응답보다 품질이 떨어지는 입력을 통합할 때에도 출력 품질을 유지하거나 향상시켜야 한다.
본 논문에서는 많은 LLM이 집합자와 제안자로서의 능력을 모두 갖추고 있고, 특정 모델이 뚜렷한 역할에 대한 전문성을 보유하고 있음을 나타낸다.
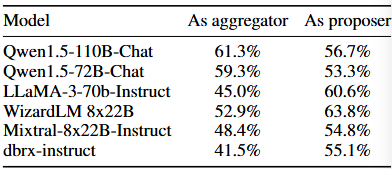
GPT-4o, Qwen1.5, LLaMA-3는 제안자, 집합자 모두 다재다능한 모델로 나타났다.
반면 WizardLM은 집합자의 역할을 하는 데 어려움을 겪었다.
집합자가 다른 모델의 출력을 기반으로 높은 품질의 응답을 생성하는 것을 고려하여, 추가 집합자를 도입하여 협력을 더욱 강화하는 것을 제안한다.
직관적인 방법 중 하나는, 여러 집합자를 사용하여 답변을 집합 후, 집합한 답변을 다시 한번 집합하는 것이다. 프로세스에 더 많은 집합자를 포함함으로써, 보다 우수한 결과를 도출할 수 있다.
Mixture-of-Agents
MoA의 구조는 앞서 보았듯이 다음과 같다.
LLM은 동일한 Layer 내에서, 또는 다른 Layer에서 재사용될수 있다는 점에 유의하는 것이 중요하다.
같은 Layer에서 여러 LLM이 동일하다, 이 구성은 모델이 여러개의 서로 다른 출력을 생성하는 특수한 구조로 이어진다.(temperature sampling에 따른 확률적 성질)
이를 단일 제안자(single-proposer)이라고 하며, 여기서는 활성화된 모델의 드문 부분 집합만 존재한다.
LLM Ai,j는 input text를 처리하고 그 연속성을 생성한다. 이 방식은 Fine-Tuning이 필요하지 않으며, LLM의 prompt와 생성 인터페이스만을 사용한다.
공식적으로는, input prompt x1이 주어지면 i번째 MoA층의 출력 y1은 다음과 같이 표현될 수 있다.
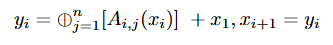
‘+’는 text의 연결을 의미하고, ‘⊕’는 Aggregate-and Synthesize prompt를 적용한 것을 의미한다.
실제로, prompt와 모든 모델 응답을 연결할 필요가 없으므로 마지막 Layer에서 하나의 LLM만 사용하면 된다.
- Aggregate-and-Synthesize Prompt

표 1: 다른 모델의 응답을 통합하기 위한 집계 및 합성 프롬프트. 최신 사용자 쿼리에 대한 다양한 오픈 소스 모델의 응답 집합이 제공되었습니다. 귀하의 작업은 이러한 응답을 고품질의 단일 응답으로 합성하는 것입니다. 이러한 응답에 제공된 정보를 비판적으로 평가하는 것이 중요합니다. 응답에 제공된 정보 중 일부가 편향되거나 부정확할 수 있음을 인식하고 비판적으로 평가하는 것이 중요합니다. 답변은 주어진 답안을 단순히 답습하는 것이 아니라 세련되고 정확하며 포괄적인 답안을 합니다. 답변이 체계적이고 일관성이 있으며 최고 수준의 정확성과 신뢰성을 준수하는지 확인합니다.
모델의 답변:
- [Ai의 모델 응답,1]
- [Ai의 모델 응답,2]
…
n. [Ai,n의 모델 응답]
Analogy to Mixture-of-Experts
MoE는 다양한 skill set에 대해 multiple expert network로 잘 알려진 머신 러닝 기술이다.
MoE 접근 방식은 복잡한 문제 해결 task를 위한 다양한 모델 능력을 활용할 수 있다는 접근이다.
본 논문에서 제안한 MoA 방봅은 MoE 방법론에서 영감을 받았다고 한다.
기본적인 MoE 설계는 MoE Layer로 알려진 여러 Layers의 집합으로 구성된다.
각 Layer는 n개의 exepert network와 gating nework로 구성되어 있으며, residual connection을 통해 gradient flow를 향상시켰다.
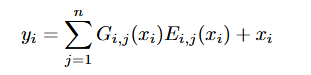
Layer i, 전문가 j의 gating network 출력 Gi,j, expert network j가 계산한 함수 Ei,j로 구성되어 있다.
고차원적인 관점에서, MoA는 MoE 개념을 모델 레벨로 확장하여 활성화 레벨이 아닌 모델 레벨에서 작동한다. 구체적으로, MoA 접근법은 LLMs를 활용하고 가중치 업데이트, 내부 활성화를 요구하지 않고 완전히 prompt interface를 통해 작동한다.
이는 MoE와 같은 단일 모델 내에 전문화된 하위 network를 두는 대신, Layers를 거쳐 여러 완전한 LLM을 활용하는 것을 의미한다.
MoA에서는 LLM을 활용하여 gating network와 expert network의 역할을 통합하므로, LLM의 intrinsic capacity(내재적 용량)가 input을 해석하고 응집력 있는 출력을 생성하여 가중치 업데이트 없이 효과적으로 정규화할 수 있게 한다.
또한, 기존 모델에 내재된 prompt 기능만 의존하므로
- Fine-Tuning에 따른 계산 overhead를 제거한다.
- 유연성&확장성을 제공: MoA는 모델의 크기나 아키텍처에 관계없이 최신 LLM에 적용될 수 있다.
3. Evaluation
MoA에 대한 포괄적인 평가를 제시한다. 본 논문에서의 발견은 다음과 같다.
- AlpacaEval 2.0, MT-Bench, FLASK Benchmark에서 개선 달성, 오픈소스 모델만을 사용할 경우AlpacaEval 2.0, FLASK에서 GPT-4o를 능가
- MoA 내부 매커니즘에 대한 더 나은 이해를 제공하기 위해 광범위한 실험 수행
- 예산 분석을 통해, MoA 구현이 2배 효율적이며 GPT-4 Turbo에 비견되는 성능을 제공할 수 있음을 보여준다.
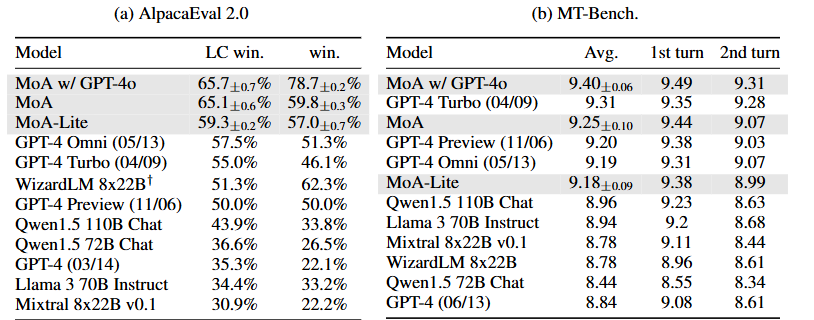
MoA, MoA-Lite는 각각 3,2 Layers가 있는 6개의 proposer를 나타낸다.
MoA w/ GPT-4o는 aggregator로 GPT-4o를 사용한 것을 의미한다.
Setup - Benchmark
- lpacaEval 2.0: 실제 사용 사례를 대표하는 805개의 instruction. 모델의 응답은 GPT-4와 직접 비교하고, GPT-4기반 평가자가 평가 대상 모델의 응답을 선호할 가능성을 판단한다. 평가의 공정성을 위해 길이 편향을 효과적으로 중화하는 LC win rates를 사용한다.
- MT-Bench: GPT-4를 사용하여 모델의 답변에 대한 점수를 매긴다.
- FLASK: 12개의 스킬별 점수로 좀 더 세분화된 평가를 제공한다.
Setup - Models
기본 MoA는 오픈 소스 모델을 사용하여 구성하였다. 오픈 소스 모델에 대해서는 모든 추론이 Together Inference Endpoint를 통해 수행되었다.
- Qwen1.5-110B-Chat
- Qwen1.5-72B-Chat
- WizardLM-8x22B
- LLaMA-3-70B-Instruct
- Mixtral-8x22B-v0.1
- dbrx-instruct
3개의 MoA Layer를 구성하고 각 Layer에서 동일한 모델 세트를 사용하며, 마지막 Layer에서는 Qwen1.5-110B-Chat을 aggregator로 사용한다.
변형 MoA는 고품질 출력을 우선시하기 위해
- GPT-4o를 최종 MoA Layer에서 aggregator로 사용하는 MoA w/GPT-4o 변형과,
- 비용 효율성을 강조하기 위해 2개의 MoA Layer만 포함하고 Qwen1.5-72B-Chat을 aggregator로 사용하는 MoA-Lite 변형을 개발했다.
Benchmark Results
- AlpacaEval 2.0
MoA, MoA-Lite 모두 GPT-4o를 능가하였다. 컴퓨팅 예산에 따라 오픈 소스 모델의 능력을 최대한 활용하는 방법의 효과성을 강조한다.
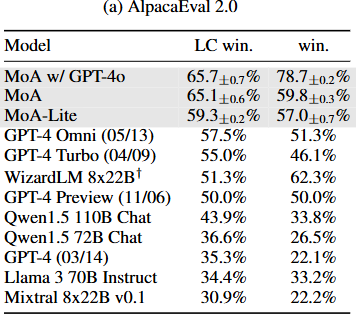
- MT-Bench
개별 모델에 대한 개선이 상대적으로 점진적이지만, 현재 모델들이 이미 이 Benchmark에서 뛰어난 성능을 보여주고 있다. 단일 모델만으로도 10점 만점에 9점 이상 달성할수 있다.
미미한 개선에도 불구하고, MoA는 여전히 리더보드에서 최고 위치를 확보하고 있다.
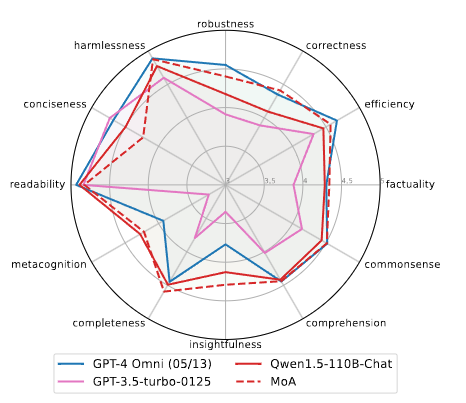
- FLASK
모델에 대한 세밀한 평가를 제공한다.
MoA는 Qwen-110B-Chat aggregator 모델의 단일 모델 점수와 비교했을 때 robustness, correctness, efficiency, factuality, commonsense, insightfulness, completeness에서 상당한 개선을 보여준다.
또한 correctness, factuality, insightfulness, completeness, metacognition 측면에서도 GPT-4o를 능가한다.
MoA가 좋지 않은 유일한 지표는 conciseness로, 이 모델은 다소 더 장황한 출력을 생성했다.
What makes Mixture-of-Agents Work well?
내부 매커니즘에 대한 이해를 돕는 실험을 수행한다.
- Mixture-of-Agents significatly outperforms LLM rankers.
MoA는 LLM rankers보다 우수한 성능을 발휘한다. MoA가 단순히 prompt가 생성한 답변 중 하나를 선택하는 것이 아니라, 모든 제안된 생성을 종합적으로 활용하여 더 정교한 방식으로 aggregation하기 때문이다.
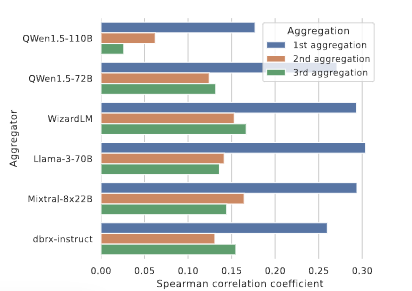
- MoA tends to incorporate the best proposed answers.
MoA는 win rates와 BLEU 점수 사이에 긍정적인 상관관계가 있음을 보여준다. 즉, MoA는 제안된 답변 중 가장 좋은 답변을 통합하는 경향이 있다. 유사도 측정 방법으로 BLEU 외에 Levenshtein similarity나 TF-IDF를 사용해도 유사한 결과를 얻을 수 있다.
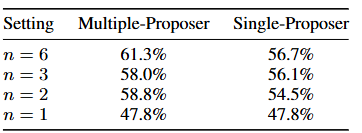
- Effect of model diversity and the number of proposers.
proposers가 많을수록 최종 품질이 향상된다. 더 많은 보조 정보가 제공되기 때문이다.
또한, 다양한 LLM을 사용하는 것이 동일한 LLM에서 여러 응답을 생성하는 것보다 더 나은 결과를 가져온다.
MoA의 폭을 추가로 확장하는 것은 향후 연구에서 유망한 방향이다.
- Specialization of models in the Mixture-of-Agent ecosystem.
일부 모델은 Proposer과 Aggregator task에서 효과적으로 작동하나, 어떤 모델은 proposer모델로서 뛰어난 성능을 보인다. GPT-4i, Qwen, LLaMA-3는 다재다능한 모델로 나타났으며, WizardLM은 Proposer model로 뛰어난 성능을 보였다.
Budget and Token Analysis
cost, Token 사용, LC win rates 간의 관계를 이해하기 위해 분석을 수행했다.
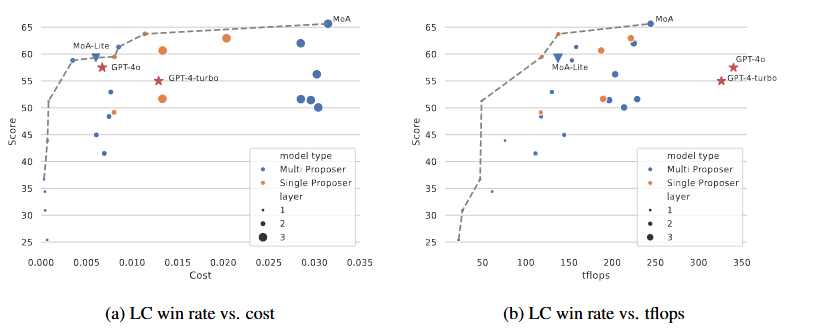
MoA, MoA-Lite의 cost 효율성을 분석하고, TFLOPs를 사용하여 latency를 추정한 결과이다. 일반적으로 Layers 수가 많을수록 성능이 향상되는 것을 볼 수 있다.
- Pareto front: 주어진 비용 또는 TFLOPs에서 가장 높은 LC win rates를 달성하는 모델들을 연결한 선이다. 이 선보다 위에 있는 모델들은 특정 cost 대비 성능이 가장 뛰어나다는 것을 의미한다.
- Cost Effectiveness: MoA 모델은 Pareto front에 위치한다. MoA-Lite는 GPT-4o와 비슷한 비용으로 더 나은 품질을 제공하여 균형을 이룬다. MoA-Lite는 GPT-4 Turbo보다 저렴하면서도 성능이 우수하다.
- TFLOPs Comsumption: 여기서도 MoA 모델이 Pareto front에 위치하는 것을 볼 수 있다. MoA 모델은 계산 자원을 효과적으로 활용하여 LC win rates를 극대화한다.
4. Related Work
LLM 추론(LLM Reasoning)
LLM의 생성 품질을 개선하기 위해 다양한 downstream task에 대해 LLM 최적화에서 큰 진전을 이뤘다.
- Chain of Thought(CoT) prompting
각 단계가 이전 단계에 기반하여 이루어지는 선형 문제 해결 접근 방식을 나타낸다.
Fu et al.(2022)는 CoT를 다단계 추론 작업에 적용했다.
- Auto-CoT (Zhang et al., 2022b)
CoT를 자동화하기 위해, Auto-CoT는 다양한 질문을 샘플링하고 추론 Chain을 생성하여 시연을 구성한다.
- Active-prompt (Diao et al., 2023)
특정 task의 annotation을 위해 가장 불확실한 질문을 선택하는데 중점을 둔다.
- PS Prompt (Plan-and-Solve Promptng, Wang et al., 2023)
task를 하위 task로 분해한다.
- Tree-of-Thought (ToT, Yao et al., 2023a)
추론 과정에서 여러 추론 경로를 고려하고 선택 사항을 자체 평가하여 추론 프로세스를 확장한다.
- Natural Program prompting (Ling et al., 2023)
연역적 추론 task를 더 잘 해결하기 위해 제안되었다.
- Re-reading prompt (Xu et al., 2023b)
입력 prompt에 포함된 질문 정보를 다시 검토한다.
Model Ensemble
모델 앙상블은 여러 모델의 강점을 활용하는 간단한 방법이다.
- 다양한 모델의 출력 재정렬
LLM-blender에서는 PAIRRANKER를 소개하며, 쌍별 비교를 통해 최적의 결과물을 선택하여 자체 구축한 instruction 데이터셋에서 성능 향상을 보여준다.
- LLM의 효율적인 cost
FrugalGPT는 LLM cost를 줄이기 위해 cascading(계단식) 방식으로 여러 모델을 사용하는 방법을 제안한다.
- multi-agent collaboration
여러 LLM을 Agent로 활용하여 주어진 문제에 대해 토론하고 추론하는 연구도 진행중이다.
du et al.,(2023)은 Agent간의 대칭 토론을 위한 매커니즘을 구축했다.
같은 시기에 MAD(Liang et al., 2023)는 서로 다른 역할인 논쟁자와 판사가 있는 비대칭 매커니즘을 설계하였다.
MoA 방법론은 여러 LLM의 collective expertise(집단 전문성)를 활용하여 더 강력하고 robust한 모델을 만드는 것을 목표로 한다.
이러한 연구들은 서로 다른 LLM을 결합하여 시너지를 창출하고, 개별 모델의 한계를 극복하고자 한다.
5. Conclusion
여러 LLM의 능력을 활용하기 위해 Mixture-of-Agent 접근법은 제안한다.
MoA를 통해 Agents의 집단 전문성을 활용하여 개별 모델의 출력 품질을 크게 향상시킬 수 있다.
AlpacaEval 2.0, MT-Bench, FLASK에서 상당한 개선을 보여주었으며, LC win rates는 65%까지 달성했다.
이러한 발견들은 다양한 모델의 관점을 통합하는 것이 단일 모델에 의존하는 것보다 우수한 성능으로 이어질 수 있다는 본 논문의 가설을 입증한다.
또한, MoA 설계를 개선하기 위한 통찰을 제공하며, MoA 구조의 체계적인 최적화가 향후 연구에 있어 흥미로운 방향임을 알린다.
Limitations.
제인 방법론은 모델 응답을 반복접으로 집계해야 하며, 이는 모델이 마지막 Layer에 도착할 때까지 첫번째 Token을 결정할 수 없음을 의미한다.
이로 인해 첫번째 Token 발행 시간(Time to First Token, TTFT)이 길어져 사용자 경험에 부정적인 영향을 미칠 수 있다.
문제를 완화하기 위해 MoA Layers 수를 제한할 수 있다. 첫번째 aggregation에서 생성 품질의 가장 큰 향상이 이루어지기 때문이다.
향후 연구에서는 전체 응답을 한번에 aggregation하는 대신 chunk단위 집계를 탐색하여 TTFT를 줄이면서도 응답 품질을 유지할 수 있을 것이다.
Borader Impact.
MoA는 LLM 기반의 chat assistant의 효과성을 향상시키고, AI의 접근성을 높일 수 있는 잠재력을 지니고 있다.
중간 결과물이 자연어로 표현되므로 모델의 해석 가능성을 향상시켜 인간의 추론과 더 잘 일치하도록 할 수 있다.
6.Appendix
MoA, MoE, 앙상블
개념 설명 모델 선택 방식 주요 활용 분야
| MoA | 여러 개의 Attention 모듈을 조합 | 여러 Attention을 가중합하여 조정 | NLP, Computer Vision |
| MoE | 여러 개의 전문가(Experts) 중 일부만 활성화 | Gating Network가 Experts 선택 | 대규모 언어모델, 추천 시스템 |
| 앙상블 | 여러 개의 독립적인 모델을 결합 | 모든 모델의 예측을 결합 | ML, DL 전체 |
MoA 아키텍처에서 TTFT(Time to First Token)이 증가하는 이유
여러개의 LLM이 계층적으로 협력하여 최종 응답을 생성하는 구조이므로, 최종 MoA 계층에 도달하기 전까지는 첫번째 토큰을 생성할 수 없으므로 TTFT가 길어질 수 있다.
MoA 아키텍처의 구조:
- Proposer 계층: 각 계층에서 여러 개의 LLM이 주어진 입력에 대해 개별적인 응답을 생성
- Aggregator 계층: 생성된 응답들을 집계하여 하나의 통합된 응답을 만듭니다. 이 통합된 응답은 다음 계층의 입력으로 사용
- 계층 반복: 이러한 과정이 여러 계층에 걸쳐 반복되며, 각 계층은 이전 계층의 출력을 기반으로 새로운 응답을 생성하고 집계