
처음으로 논문을 읽고 복기하며 정리해보려고 한다.
"Attention Is All You Need"는 Google 소속 과학자 8명이 2017년에 작성한 연구논문이다.
기존 RNN,CNN의 병렬 처리가 불가능했던 문제를 본 논문에서 트랜스포머(Transformer) 아키텍처를 제안하여 화제가 되었고 이를 활용하여 머신러닝 분야에서 정말 많은 것이 바뀌었다고 한다.
우선, 어텐션과 셀프 어텐션의 개념을 이해하는데 생각보다 힘들었어서, 정리해놓고 틈틈히 확인해보려고 먼저 정리해보았다.
Attention vs. Self-Attention

위 예시 문장에서, "Who is the singer?" 라는 질문을 하게 된다면, 단어 하나하나 주어진 정보들을 조합하여 'singer'와의 관련성을 확인해야 할 것이다. 이러한 과정에서 시퀀스가 길어질수록 기울기 소실/폭발 문제가 발생할 수 있다.
Attention을 통해 아래와 같이 주목해야 할 단어에 더 높은 가중치를 부여하여 집중하면 얻고자 하는 출력값을 효율적으로 얻을 수 있을 것이다.

Self-Attention은 이름에서 짐작할 수 있듯이 주어진 문장 내에서 단어들 관의 관계(연관성)을 고려하여 Attention을 계산하는 과정이다.

Self-Attention을 통해 문장 내에서 단어들 간의 관계를 파악한다면, 빨간색 tear(찢다)와 파란색 tear(눈물)의 유사도(분산 표현 벡터)가 다를 것을 유추할 수 있다.
Query,Key,Value가 Self-Attention의 입력값으로 들어가는데, 좀 더 자세히 설명해보도록 하겠다.
Self-Attention의 전체적인 흐름을 단계적으로 보자.
1. Linear Layer

각각의 Linear Layer에는 동일한 Emb+Pos(Embedding계층 + Positional Encoding)이 입력된다.
그 이유는, Q,K,V 각각의 차원을 줄이고, 행렬의 형상을 통일해 병렬 연산에 적합한 구조를 만들기 위함이다.
Positional Encoding은 논문에서 언급되니 뒤에서 확인해보자. 간단히 말하자면, 임베딩 벡터에 순서를 기억시키기 위해 sin,cos값을 더해준다.

2. Attention Score
Linear 연산을 통해 같은 형상의 Q,K,V를 얻게 된다.
먼저 Q,K행렬을 내적하면 아래 그림처럼 Attention Score을 얻게 된다. (전치행렬 K)

Attention Score란 Q,K 행렬간의 유사도를 의미한다. 아래 예를 확인해보자.
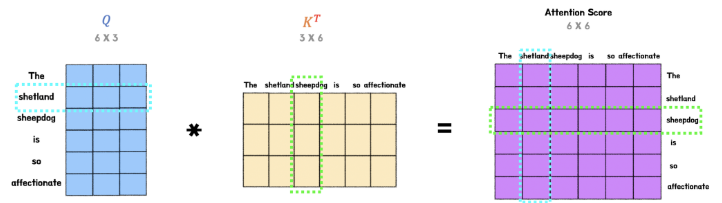
위 그림과 같이, 해당 단어들이 교차하는 인덱스 지점에 두 단어의 유사도가 저장되어 있다고 생각하면 된다.
우선, 코사인 유사도 공식을 다들 알 것이다. 두 벡터가 얼마나 유사한지(의미적으로) 계산할 수 있는 수식이다.
벡터의 크기는 고려하지 않고 방향만 고려하는데, 코사인함수 특성상 값은 -1~1 사이의 실수이다.
1에 가까울수록 유사도가 높고, -1에 가까울수록 유사도가 반대(뜻이 반대)이다. 수식을 보자.

코사인 유사도는 벡터의 곱을 두 벡터의 L2 Norm 곱, 즉 scaling으로 나눈 값이다.

코사인 유사도 식을 토대로 우리는 Q,K간의 행렬 유사도도 구할 수 있게 된다.
위 수식은 Query, Key간의 유사도 행렬 계산식이다. scaling은 바로 밑에서 설명하기에 건너뛰고, 위 유사도를 통해 softmax함수를 사용해 정규화 및 확률을 출력하여 최종 Attention Value를 얻는다.

3. Scaling & Softmax
Attention Score를 Scaling과 Softmax를 통해 확률로 해석할 수 있도록 한다.
Attention Score의 수식은 다음과 같다.

이때 dk는 벡터의 차원(보통 모델 차원 dmodel을 멀티 헤드의 값으로 나눈 값)이다.
여기서 scale은 1/(dk)^1/2로 표현된다.
그럼 왜 scale이 필요할까? 위식에서 Q,K(전치행렬)곱은 점곱으로, 값이 지나치게 크거나 작아질 수 있다.
적절한 scaling을 통해 분산을 일정하게 유지하며 Softmax함수가 더 안정적으로 동작하게 한다.

마지막으로 Attention Score와 V(value)를 내적하면 Self-Attention Value를 구하게 된다.
이 과정이 Self-Attention의 전체적인 흐름이다.

Attention Is All You Need(2017)
1. Introduction

RNN 기반 모델인 LSTM의 구조도이다. 이전 시각의 정보를 통해 t 시각의 계산을 하는 순차적인 특성 때문에, 훈련 샘플 내에서 병렬화가 불가하며, 이는 시퀀스 길이가 길어지면 메모리 제약이 샘플 가의 배치를 제약한다.
최근 연구에서는 factorization tricks과 conditional coputation을 통해 효율성에서 개선과 모델 성능을 향상시키기도 했다.
하지만 순차 계싼의 근본적인 제약은 여전히 존재한다.
이러한 한계점을 개선하기 위해 본 논문에서는 Transformer라는 새로운 네트워크 아키텍처를 제안한다.

Transformer Encoder의 구조도를 보면, 한 문장에 대한 토큰(단어)들이 순차적인 것이 아닌 한번에 입력된다.
이후 Attention을 통해 문장 내에서 단어들의 관련성을 분산 표현 벡터로 저장한다.
2. Background
Transformer의 목표는 순차적인 계산을 줄이는 것이다.
이전 모델인 Extended Neural GPU, ByteNet, ConvS2S는 CNN을 기반으로 하여 입출력의 모든 위치를 병렬로 처리한다. 이 모델들은 두 신호간 관계를 성립시키기 위해 두 신호 사이의 거리에 따라 연상량이 증가하는데, 이는 종류에 따라 선형적으로(ConvS2S), 또는 로그적으로(ByteNet) 증가한다. 이는 멀리 떨어진 위치간의 의존성을 학습하는데 어려움을 초래한다.
Transformer에서는 위 연산량이 상수로 감소한다. 또한, 오로지 Self-Attention에 의존하는 최초의 전이(transduction) 모델이다. 이로 인해 전역 의존성을 모델링하고 더 많은 병렬 처리가 가능하게 된다.
3. Model Architect

우선, 총 6개의 Nx(Encoder와 Decoder)로 이루어져 있으며, Nx는 하이퍼파라미터이다.
위 실험에서는 Nx = 6에서 최적의 결과가 나왔기 때문에 Default값으로 생각한다.

논문에서 제안한 Transformer의 전체적인 구조이다.
각 계층의 구조 설명을 해보겠다.
1. Embedding & Data Tokenizing
자연어를 단어 단위로 나누고(토큰화) 임베딩 계층을 통해 고정된 벡터의 크기로 변환한다.
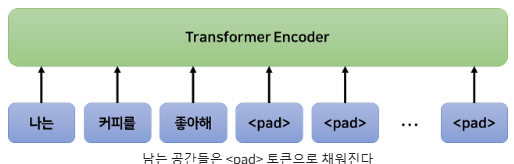
Transformer는 RNN기반의 방법과 달리 고정된 길이의 입력을 받는다.
공간이 남는다면 <pad> 토큰을 넣고, 입력 데이터가 더 크다면 분할하여 입력한다.
2. Positional Encoding
Transformer는 입력 데이터들을 순차적으로 받는 RNN과 달리 한번에 모든 데이터를 입력받기 때문에 각 토큰들의 순서를 알 수 없다.
자연어에서는 순서가 매우 중요한 의미가 있기 때문에, Positional Encoding을 통해 각 토큰에 순서 정보를 담는다.

위 수식에 따라 Embedding Vector에 작은 벡터값(PE)를 더해주는 방식으로 수행된다.
벡터의 차원이 짝수일경우 sin, 홀수일경우 cos함수를 이용한다.
3. Encoder
위에서 설명한 Self-Attention 구조를 떠올려보자.
Multi-Head Attention은 쉽게 말하자면, Self-Attention의 병렬화 학습 버전이다.
여러 부분에 동시에 어텐션을 가할 수 있어 모델이 입력 토큰간의 다양한 유형의 종속성을 포착하고 동시에 모델이 다양한 소스의 정보를 결합할 수 있게 된다.
"Which do you like bettter, coffee or tea?" 라는 문장을 예로 들어본다면,
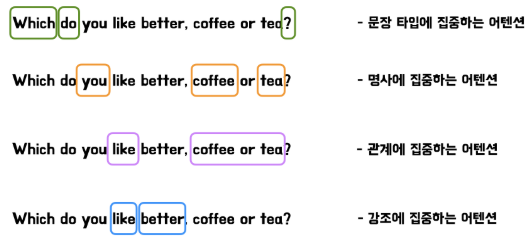
위 그림과 같이 Head들이 문장 내 여러 관계 또는 다양한 소스정보를 나타내는 정보들에 집중하는 Attention을 줄 수 있다. 즉, 표현력이 향상될 수 있고 토큰간의 미묘한 관계 역시 더 잘 포착할 수 있게 된다.
Multi-Head Attention은 Q,K,V 행렬(벡터)을 nhead개로 나눠 수행한다.
예를 들면, nhead=2라면 Q,K^T(Q, 내적을 위한 전치행렬),V가 각각 512 X 512의 형상을 갖고있었다면
각 행렬의 형상은 512 X 256, 256 X 512, 512 X 256이 되어 계산을 수행할 것이다.
이후, Attention 결과 행렬을 얻었다면 Residual Connection과 Layer Normalization을 적용한 후 concatenate를 한다.
Residual Connection(잔차연결)은 학습이 안정적이고 빠르게 수렴하게 한다.
Layer Normalization은 각 데이터의 열에 대하여 Normalization을 적용한다.
마지막으로 완전연결계층 2개와 Layer Normalization, Dropout으로 구성된 Feed Forward를 통과한 후, 다시 한번 residual connection과 layer normalization을 적용하면 마침내 하나의 Encoder를 통과한다.
4. Decoder
Transformer의 Decoder는 입력 데이터에 이어질 토큰을 인코더의 출력을 기반으로 예측한다.
그럼, Transformer는 RNN과 다르게 한번에 모든 입력 데이터를 받는데 미래 시각의 데이터를 참조 할 수 있는거 아닌가? 라는 생각이 들 수 있을 것이다. 이 문제를 해결하기 위해 Masked Multi-Head Attention 계층이 추가된다.

위 그림에서 보듯 Mask는 Scale 연산 후 Sofmax 전에 수행된다.
현재 단어를 예측할 때, 미래 단어에 대한 정보를 사용할 수 있기 때문이다.

Mask 기법인 Look-ahead Mask는 Decoder가 현재 단어보다 미래에 오는 단어들을 참조하지 못하도록 -inf로 Masking 처리한다. 컨닝방지 기법이라고 이해하면 편할 것이다. (행렬으 대각선 위)
이후, Softmax를 적용한다면 -inf는 확률 0을 갖게 될 것이다. 아래 그림을 참고하자.
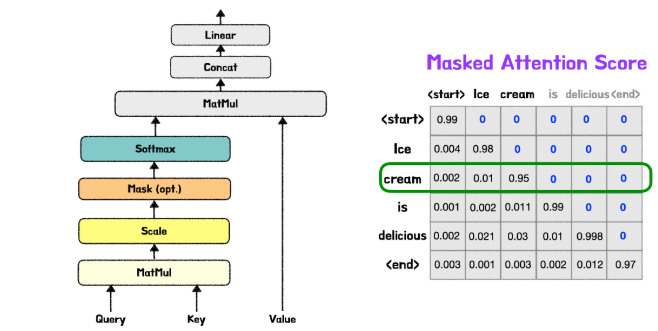
Decoder가 Encoder와 또 다른 점이 하나 있다.
Encoder에서는 Q,K,V가 모두 동일한 소스에서 생성되나, Encoder-Decoder Attention에서는 Q,K,V가 서로 다른 소스에서 생성된다. 아래 그림을 보자.

그림을 보게 되면 K,V는 Encoder가 처리한 전체 입력 시퀀스에서 생선된 출력을 가져온다. Encoder의 출력은 전체 입력 시퀀스에 대한 포괄적인 표현을 담고 있다.
Q는 현재 시각에서 Decoder가 다음에 생성할 단어에 필요한 정보를 찾는 역할을 한다.
이렇게 생성된 Q는 Key와 Value간의 관계를 통해 필요한 정보를 추출하여 Decoder의 다음 출력 예측에 활용된다.
위 과정을 통해 Decoder는 입력 시퀀스 전체에 대한 정보를 바탕으로 정확한 예측을 수행할 수 있다.
4. 마치며
뒤에 실험 방식, 결과, 결론 등이 있으나 글로 정리하는 것은 생략하려고 한다.
처음 논문을 읽어봤는데 논문만 읽어서는 이해가 잘 되지 않았다.
세상에는 정말 똑똑하신 분들이 많다. 초등학생도 이해하기 쉬울 정도의 표현과 예시를 들어준 블로그들 덕분에 어느정도 Transformer의 구조가 눈에 익기 시작했다.
아래 링크는 논문을 읽으며 내가 참고한 고마운 블로그 링크들이다.
참고 블로그
https://www.blossominkyung.com/
Blossomindy's Research Blog
Recent Posts
www.blossominkyung.com
컴퓨터와 수학, 몽상 조금
컴퓨터공학, 딥러닝, 수학 등을 다룹니다.
skyil.tistory.com